2020 Retrospective
While migrating my site years later, it’s worth mentioning theres alot of wonderful toolchains available now that really nail this. The biggest one being someone put in the work to properly parse the site-maps.
Intro
Trying bug bounties can be fun, you might even walk off like a prospector with gold. Of course similar to sifting through river water looking for gold, youve got sifting through websites looking for things that catch your eye. It can be pretty repetitive, so lets get some practice in by making a tool of our own to help make this attack surface for us.
Methodology
First off, what is an attack surface?
The attack surface of a software environment is the sum of the different points (the “attack vectors”) where an unauthorized user (the “attacker”) can try to enter data to or extract data from an environment.
In this case our attack surface is the sum of all points comprising the companies web infratructure that we can reach. From there the surface widens to all methods and actions on the site that will allow us to interact with the back end.
Visualized a companies attack surface could look something like this, containing internet facing services alongside their internal network. Typically you wont ever see much of the latter except for in cases such as SSRF, the 10k Host Header bug bounty writeup comes to mind in particular. 10k Host Header
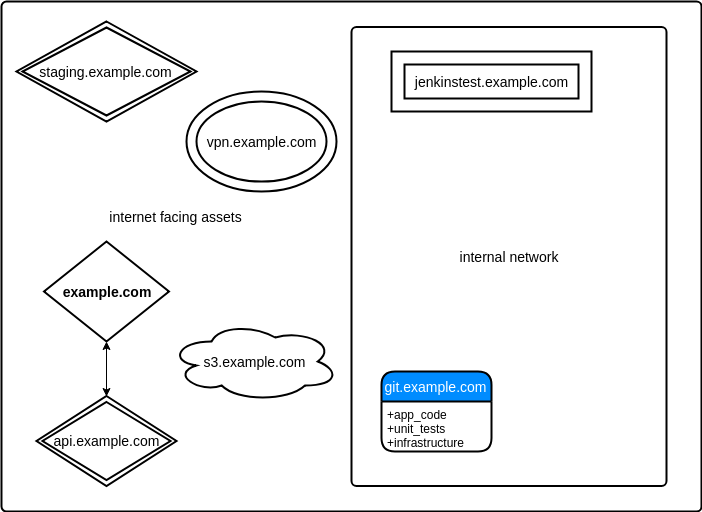
There will be plenty we dont hit due to not being discovered or out of scope. When it comes to subdomains we of course want to find things to potentially exploit as side services may be neglected, or we want to look for things that dont belong such as a public facing build server.
Next once we have a site or service targeted, we can speed up some information gathering by spidering the site to harvest all of the URLs in hopes of finding ones with parameters to interact with.
example.com/ProductID?=product_1
Ideally by looking at URLs we can spot potential ways to interact with the backend in hopes of producing some sort of undefined behavior. Of course going over attack vectors is a whole in depth topic of its own so we’ll leave it at that.
MapSnatch.py && map.py
To help us with these tasks we have MapSnatch.py and map.py
MapSnatch is our logic that will do the following:
- Spider all links off domain.com
- Find all subdomains of domain.com
- Assess the status of all subdomains (Whats the use if we cant reach it?)
- Spider all the links of subdomain.com (Pending implementation)
map is our entry point into the program, so as such you can see we wrap it in click so it functions as a command line tool, from there we can pass our params into the logic class to handle the rest of the operations.
Its pretty cool, after installing it with pip we can call it just like a cli tool.
The code that makes it all happen is pretty simple, its all in our click wrappers and setup.py
|
|
Installation
Im not a fan of reinventing the wheel so map relies on another tool to do some of its dirty work.
Sublist3r is a fantastic tool at pulling subdomains, and doing much more.
Its easy, first we pull our map repo, then cd into it and pip install -e . I recommend using a virtualenv.
While there, clone Sublist3r, install its requirements.txt , and move the files to resemble this structure
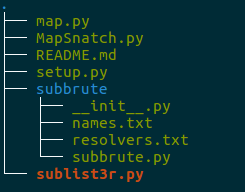
Theres no shortage of ways to package software, I just threw this together in a few hours while procrastinating on finishing a project.
Logic && Results
If you were to look at our flows as these:
get domain.com -> harvest links -> map links
discover subdomain.com -> assess status -> harvest links -> map links
then you can probably guess alot of how we would go about this.
Both are mostly pretty easy,
domain.com
- Use requests to get the content
- Use beautiful soup to parse the content
- Map results to a dict={domain_name: [‘list of links’]}
then for subdomains,
subdomain.com
- Use sublist3r to discover
- Requests to check for
statuscode==200 - Requests get content
- Bs4 to parse content
- Map results to a dict={subdomain_name: [‘list of links’]}
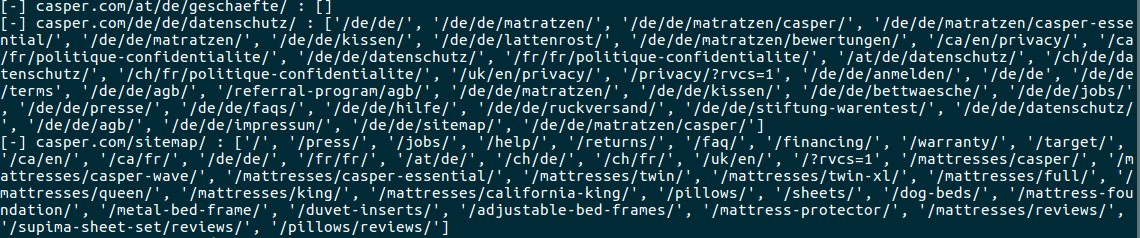
So if we were to give it a site such as casper.com heres what it looks like when its building links and we can see some with paramters.
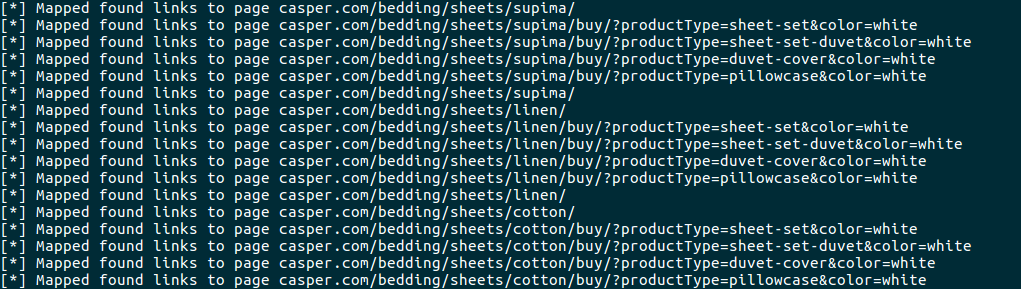
The awesome part is we didnt have to much to find those! Dont get me wrong, browsing around is half the fun.
There are plenty of better ways to visualize this, however the real goal is just give us subdomains and links to form our map of the attack surface. So for now well just leave the mapps alone.
Conclusion
A little bit of coding and we’ve got enough information gathering automated to get an overview of a site before inspecting it at a deeper level.
This can help pick a place to start or identify something our eyes may glance over and miss.
Theres no shortage of improvements or optimizations that can be made to these sorts of things. I encourage you to try and throw some tools together yourself. Itll help foster an understand of what youre doing and different methods of achieving your goals.
Happy hacking.