Intro
Recently I sat down to learn more about Go and Kubernetes, and figured I would share some distributed computing fun had along the way. Youll notice the map tool from the previous post can be slow when getting statuses, we’ll use that as a starting point and refine it.
Overview
Lets go over the core technologies at work here, starting with the most basic definition.
Container: a standard unit of software that packages up code and all its dependencies so the application runs quickly and reliably from one computing environment to another.
- Go: an open source programming language that makes it easy to build simple, reliable, and efficient software.
- Docker: a kind of container image that is a lightweight, standalone, executable package of software that includes everything needed to run an application: code, runtime, system tools, system libraries and settings.
- Kubernetes: an open-source container-orchestration system for automating deployment, scaling and management of containerized applications.
- Minikube: a tool that makes it easy to run Kubernetes locally. Minikube runs a single-node Kubernetes cluster inside a VM on your laptop
- Pods: Pods are the smallest deployable units of computing that can be created and managed in Kubernetes.
With everything laid out lets go over what we’re doing
- Virtualizing our own k8s Cluster
- Compiling our own self sufficient Go program that retrieves data and inserts it into a db
- Inserting that binary into a scratch Docker container and Testing/Running it
- Building this image and pushing to Docker hub
- Running multiple instances of the Docker image as Pods in our Kubernetes cluster
In essence everything will look roughly like this.
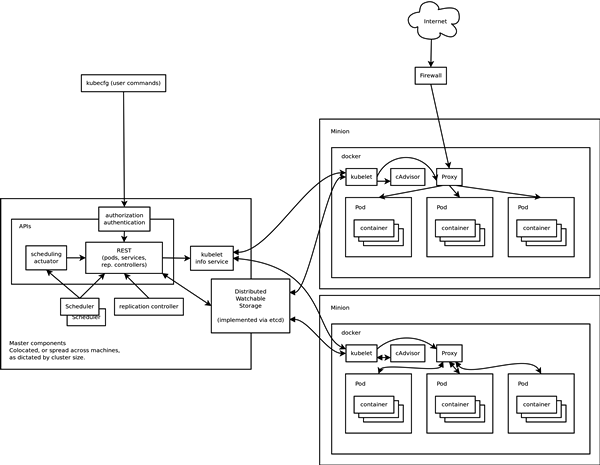
Dont worry if the visual seems overwhelming, we’ll break down simply whats going on.
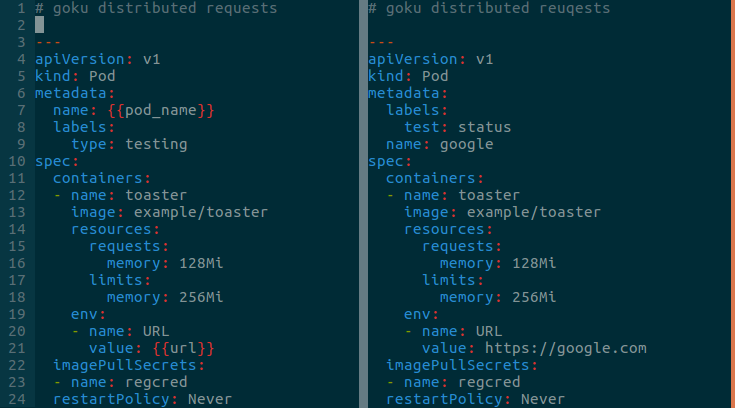
goku.go
goku.go is an incredibly small Go program. All it does is make a HTTP Get request to a URL provided through an environmental variable, then write some of the data to a database. The standalone nature of this means the program is idempotent and asyncronous.
We compile it statically with all of its dependencies included so it can be ran in a scratch Docker container, allowing us to achieve an incredibly small image size of 6.3mb. This is much more efficient and manageable from a dependency perspective than if we were trying to deal with an interpreted language like Python.
Having the URL provided by an environmental variable is what allows us to make this Go program run in a distributed manner. We can use the Python Script GenerateTargets.py to generate many different pod.yml templates with the variable set to whatever URL we want to get data from.
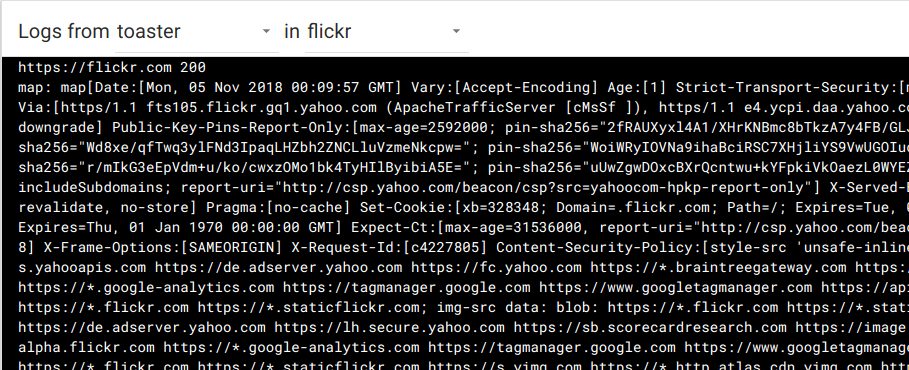
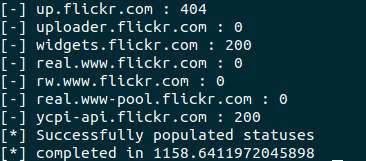
Heres what the sample output of goku.go looks like
Distributed Computing
I wanted to pick a task with a little size to it but couldnt go too crazy since Im just virtualizing all of this on my desktop, as opposed to running on a cloud kubernetes service such as EKS or GKE. In the cloud we would have autoscale groups and more resources which would make this blazing fast, however as an individual my wallet doesnt like the sound of autoscale groups.
So what we’ll do is get the status of flickr.com and its give or take 110 subdomains. Virtualizing 111 containers sounds like alot but in the pod.yml we’re able to specify memory usage allowing us to work well within our means.
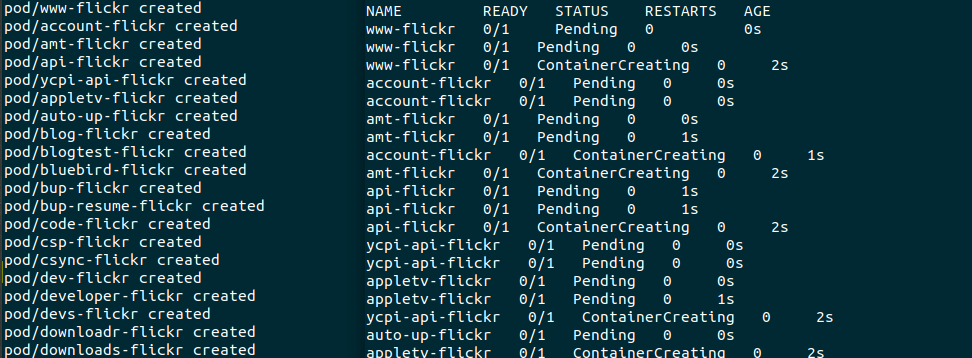
Lets kick off the bash script to create all of the pods in our cluster, and set it to –watch so we can monitor it
Since we are using Minikube, we can pop open a new terminal and type
minikube dashboard
to see this all in a cool display
After a couple a minutes we already have results
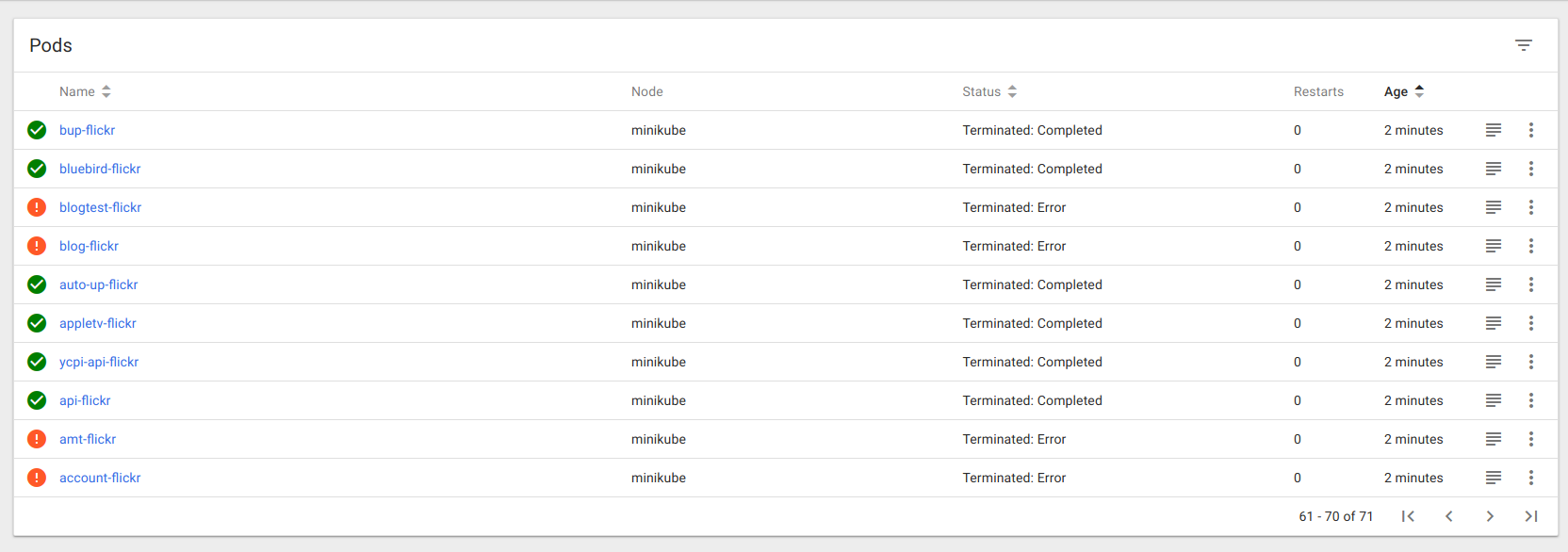
Only a single node (my desktop) is being used here so it takes more time to create all the pods, on a cloud provider it would be much much faster.
We can also take a look at resource utilization as this is all being ran. This picture as taken at the peak.
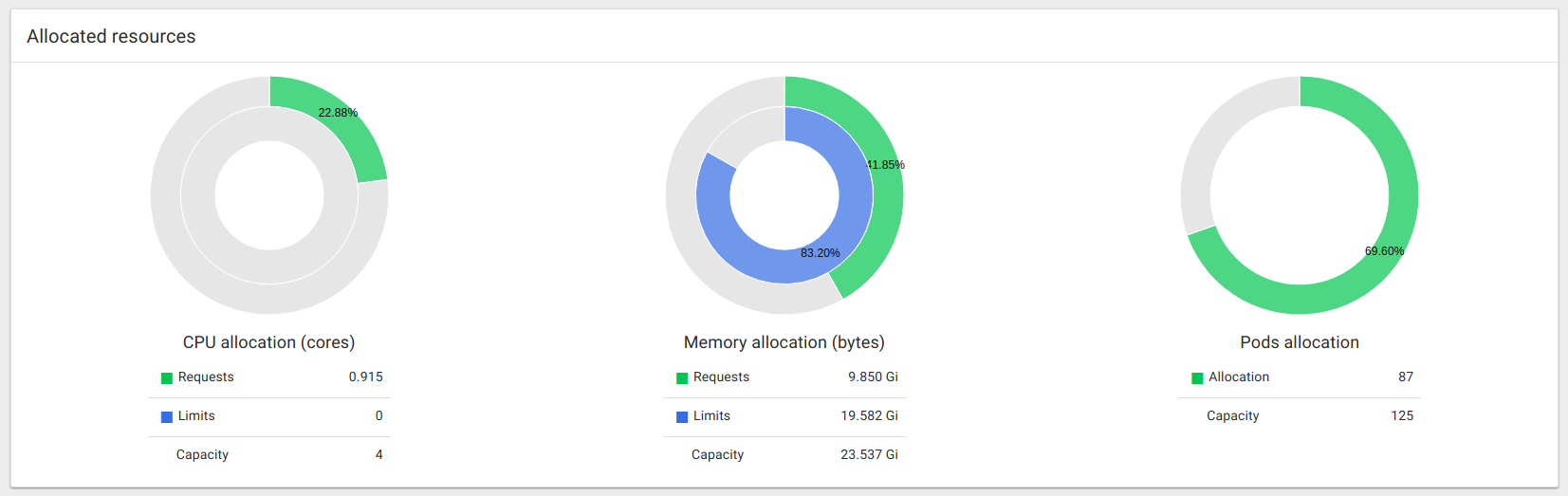
While pods are in various states the number will go up and down until all the work is complete.
Results
It took about 8 minutes to gather information from all 111 sites.
Querying the db shows that it received data from the pods.

Now if we run the map tool from my previous post and have it get the statuses, it takes about 19 minutes.
Conclusion
Surprisingly the minkube virtualized kubernetes cluster was able to perform more quickly at 8 minutes, than the map python tool from my previous post that came clocking in at 19 minutes.
Pretty interesting given we had to wait on the containers to be created. Although it helps that this approach is effectively asynchronous, compared to the python tool which is single threaded.
Overall getting some practice in with Go and Kubernetes was a great way of getting more familiar with both technologies. Dont be afraid to try and make something yourself, just remember to reference the documentation.