Intro
Previously we virtualized a Kubernetes cluster on our localhost, but that is just simulating the cloud. Why dont we take GoKu to the actual cloud and see how it does? I actually tried to tie this in and scan the same 111 URLs from the last post, but it finished so fast I couldnt believe it. Lets bump things up a notch, what if we want to scan 5000+ sites?
What is scaling?
What is scalability?
Scalability is the capability of a system, network, or process to handle a growing amount of work, or its potential to be enlarged to accommodate that growth.
We actually demonstrated some local scalability in the previous post, but were hindered by the fact that we were only using a single node since we were running Minikube.
With resource optimization and configurations we were able to run 87 pods in paralell, which is pretty good for a single workstation. But what if we had the power of the cloud?
![]()
Here we will use Google Compute Platform and more specifically the Google Kubernetes Engine to handle our needs. I had considered the Amazon EKS solution since it would be trivial to Terraform, but it has limitations with its autoscale setup out the box. AWS cant natively monitor its EKS workers memory utilization without further configuration, and since memory is our main consideration here thats a big deal. Naturally GCP/GKE became the optimal choice, its Kubernetes functionality is well integrated as a first class citizen and very easy to leverage its full potential.
When we ran this test on the single node desktop, memory became our bottle neck. As this is a distributed computing model we should easily be able to remedy this by running a cluster with more nodes.
I wasnt ready to be surprised by a large GCP bill caused by autoscaling, so we will roll with the free tier and scale up with 4 nodes of their high memory machines.
Our Test
We’ll use our GenerateTargets tool from the repo to make a directory full of pod.yml just like before, except this time we’ll pick a target with alot of subdomains.
Alibaba had over 6500, worth mentioning I removed a couple hundred email servers. The sheer number of email servers alone was in the thousands.
In our terminal lets move into the manifest directory with all the targets and throw it a kubectl apply -f .
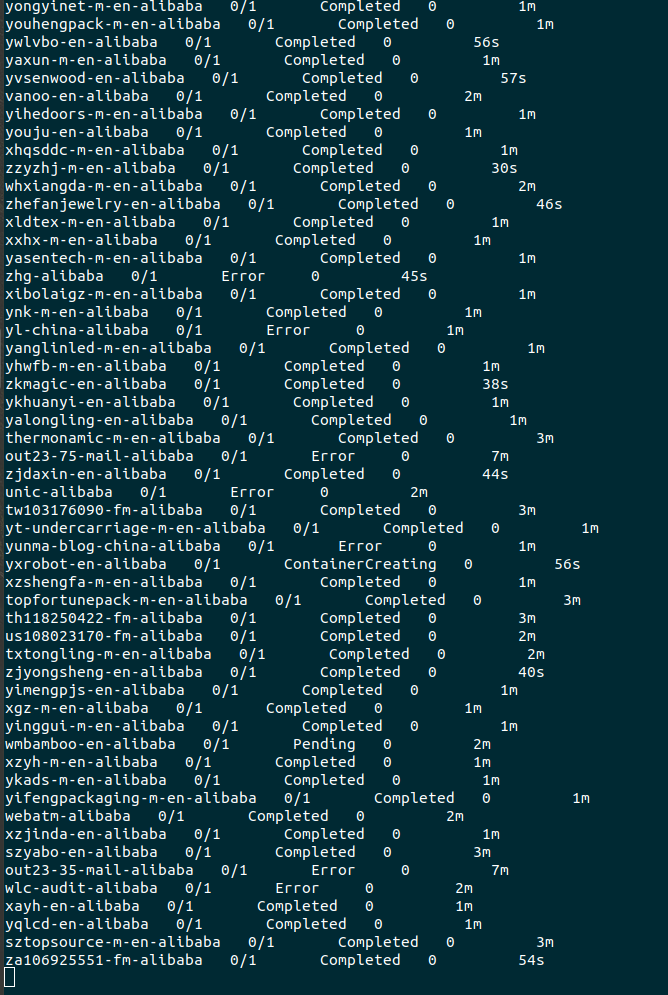
The containers are created incredibly fast and shortly move to completed. We can view this as well in our Kubernetes Workload and see that we have over a thousand pods going. Huge improvement from the 87 pods one our one node in the previous post.
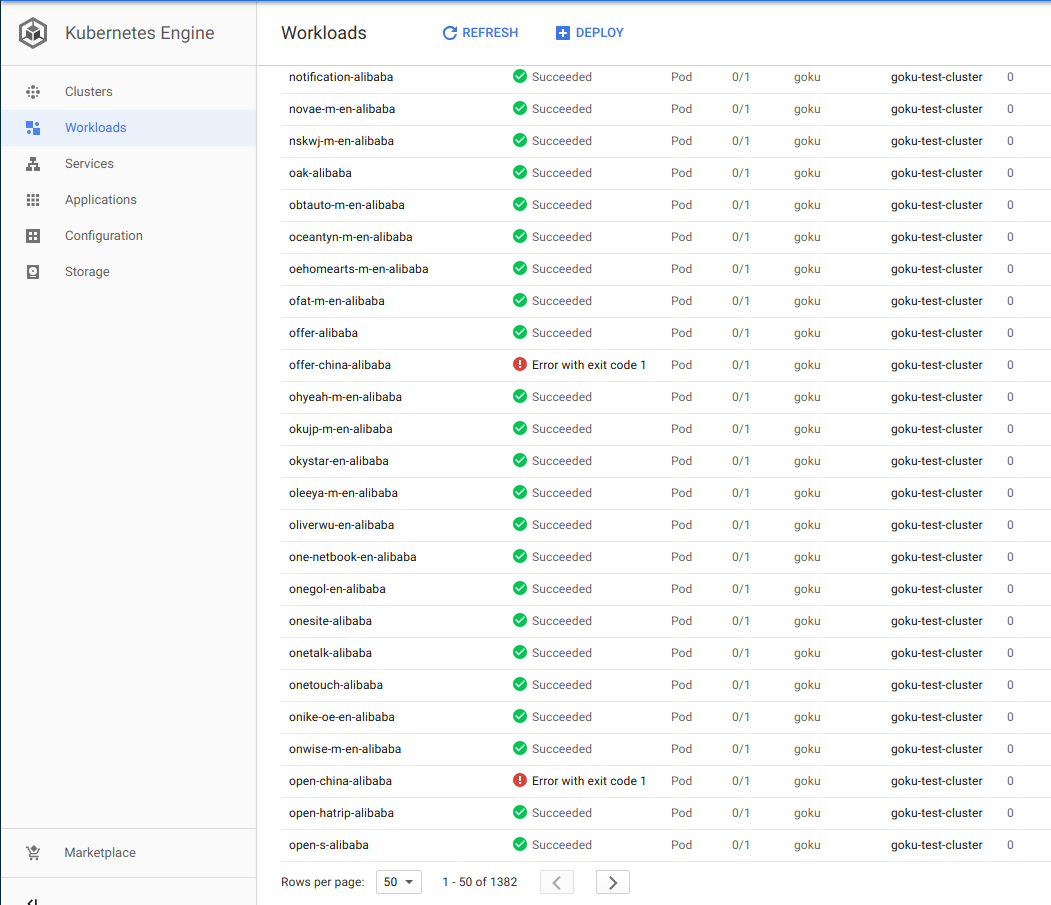
Just imagine, if thats four nodes distributing our workload, what if we had the wallet to turn autoscale on? Its likely it would scan all 5000+ in under 5 minutes.
Lets take a look at the database and see what all of this volume is doing to it.
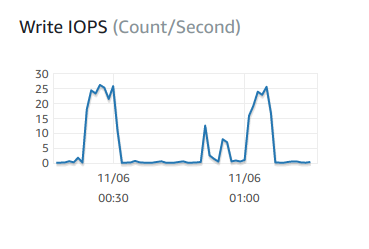
We can see the initial peak as things get ramped up, the middle as it tries to scan hundreds of email servers it cant reach, and then a second peak as it once more gets to domains that are actually in use.
The DB instance is a t2.micro in AWS RDS running MySql, for something with micro in the name it is easily handling this traffic.
##Conclusion
Here are the main findings:
- GoKu’s containerized build and Go binary made perfect for scaling container counts
- Our GKE Cluster was able to scan the 111 domains from the previous post in less than 2 minutes.
- The GKE cluster made it through all 5565 websites in about 40 minutes.
- Our database was filled with the status of over 1800 sites that were reachable
Forty minutes is insanely fast cosindering it took us 8 to scan 111 using my desktop minikube setup, of course with the power of Google Cloud Platform it should be no surprise we saw a massive increase in performance.
Now to be perfectly fair, we could just write or leverage a multi-threaded scanner that already exits.
If anyone wants to foot the autoscale bill, Id be willing to bet my setup can crunch 10000+ sites in less than 15 minutes, now thats scaling!