Intro
Slack is an effective group communication tool that Ive found myself using quite a bit recently. It simplifies communication greatly eliminating the need for multiple apps.
With Slack Im able to interact with work, side projects, and the programming community with one application.
Where Packt comes into play, is that for the last couple of weeks Ive had a colleague posting packts deal of the day in one of our slack channels daily.
So when I found a small block of free time, I decided to apply some simple automation.
Where we start
Writing a slack bot using their API and python is well documented with many examples being available. Infact I was surprised because it was probably the easiest API Ive worked with so far.
Ive also dabbled with web scraping in the past so I figured this would be incredibly quick to throw together something basic. Of course it wouldnt be any fun if I didnt hit a snag or two.
This is a recipe that has been done over plenty of times, requests to grab the page, and then BeautifulSoup to parse our what information we want.
So I threw open a python shell and just pulled the pages HTML and used BeautifulSoup to prettyprint(prettify) it, that way I could form an idea of where to go with this.
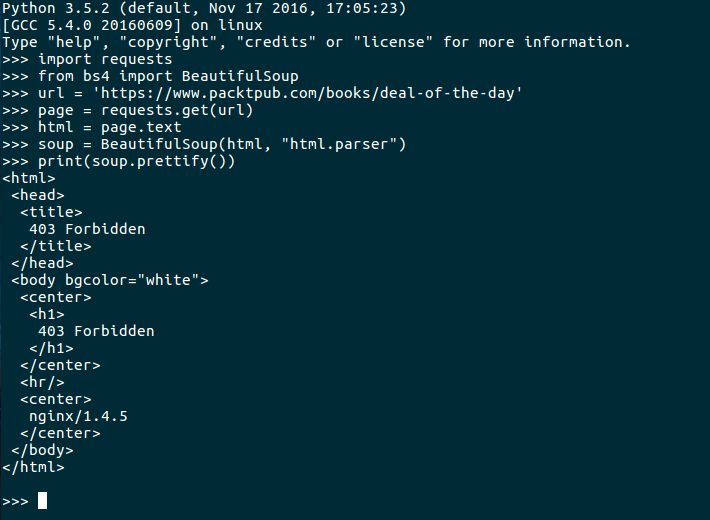
403 - Forbidden
Its common for sites to deploy some mechanisms to deter people from scraping their pages. Which is entirely fair since making alot of requests programmatically could potentially bog a site down. But in our case we only want 1 request every 24 hours. Selenium has always been my go to when scraping or testing websites, especially if Im doing a more complicated process and want to see visually what is happening. In this case though since we are pulling just one page, so going headless is much more preferred. With the magic of PhantomJS and selenium we can emulate a browser, so on the site side they see the request as coming from a ‘browser’ and dont give us the 403.
Now I simply swapped out the Requests library for BS4 and reran the script. This time around it worked great! So now that we’re pulling clean HTML, its time to get to parsing.
A little right click and inspect on the packt deal of the day page, revealed the title to be right here
<div class="dotd-title"><h2>Our Title
BS4 made quick work of this parsing and soon we get the result.
['\\n\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\tMongoDB Cookbook\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t\\t']
Woo! A new line and a bunch of tabs. Weirdly enough while I had some trouble on earlier, I dropped string.strip('\\n').strip('\\t') in the code after work and it stripped away all of those tabs.
Alright so now that we’ve got the scraping and parsing figured out, lets add our slack code in.
|
|
Results
We have acheived automation!

Conclusion
Making a slack bot to let me and my coworkers know what the deal of the day is was easy thanks to python and slacks API!
As well as the littany of other tools we put to use.
Theres just one thing though, do I really care about every free book packt has?
I barely have time to read things that interest me.
Fortunately my colleague was sharing with us things he found interesting and relevant.
Sadly my bot cant quite do that, but with the addition of a wordlist I think we can get pretty close. We can tackle that later